 大模型并行那些事:dp/pp/tp/ep/cp
大模型并行那些事:dp/pp/tp/ep/cp
# 大模型并行
众所周知,大模型训练那叫一个如火如荼,openai的chatgpt,anthropic的claude ai,xAI的Grok,还有咱中国自己的ai像豆包,deepseek等等,大家都知道scaling law (opens new window)法则,所以堆参数啊堆数据啊,那模型越做越大,想用一张卡训练不就太慢了吗,或者可能一整卡都放不下那么多训练参数对吧(总不能把东西放硬盘里吧朋友🥹),这个时候我们就需要分布式的训练了~ 顾名思义,就是用多张卡去训练一个模型——接下来就是具体问题具体分析了;
至此我们先暂时记住需要解决的两个核心问题即可:模型训练得太慢和“模型太大,一张卡放不下”(参考文献:“鲲之大,一锅炖不下”)
目前训练常用的并行主要分为
- dp并行:Data Parallelism
- tp并行:Tensor Parallelism
- pp并行:Pipeline Parallelism
- ep并行:Expert Parallelism
- cp并行:Context Parallelism
- sp并行:Seqeuence Parallelism
下面来深入浅出地各自讲一下他们具体的原理,wait,还是先讲点背景知识!
# 一些背景知识
在搞清楚并行之前,我觉得有必要给大家讲讲一些LLM训练相关的背景知识
首先如果你想了解模型结构,如Transformer的经典架构,那么可以看看这篇:Transformer结构初窥,里面记录了模型的基本架构(目前只记录了Transformer)
# 训练流程(重点)
这里主要讲讲训练的流程,以及如何影响训练的效果,个人认为这是最重要的背景知识,它将解释那些并行操作究竟如何解决那俩核心问题;
# 前向传播
前向传播可以用一个函数直接概括:
具体而言,这个model.forward可能可以拆成一大堆小的函数比如说——(这一部分如果不想看也可以暂时不看)
嵌 入 层 注 意 力 机 制 前 馈 神 经 网 络 : σ
前向传播的最后有一个损失函数,简单来说就是用来衡量“模型的输出”与“真实数据”的误差有多大,这事看起来很简单但是实际上不同的损失函数对模型训练的结果是会产生很大影响的,这里给一个链接供感兴趣的读者去看:一文彻底搞懂深度学习 - 损失函数 (opens new window)
# 反向传播
反向传播是神经网络的通用训练算法,在数据流上是前向传播的逆过程,但是算法上并不是!刚刚提到前向传播的过程中会经过一些列函数,这些函数都有一定的参数权重比如说你Embedding的时候,"oi"这个词凭什么转化成特定的浮点矩阵呢其实就是靠字典里的“权重”,比如Attention里面的Q、K、V矩阵都各自有自己的“权重”(事实上一开始都是随机初始化,或者给个正态分布之类的)而是要经过后期训练的,FFN更是不用说,
反向传播的作用就是更新这些权重,那么怎么更新呢?
欸我们先要提到一个叫梯度的东西,通俗来讲梯度提供了损失函数相对于参数的变化率信息,当梯度为正时表示损失函数随参数的增加而增加,反之则减少;通过梯度我们可以确定参数更新的方向,也就是说如果知道每个参数的梯度那就可以对每个参数更新了;

那么问题来到了如何更新参数的梯度🤓 事实上现在主流的深度学习框架 (opens new window)如Tensorflow或者Pytorch基本上都提供了高效的自动微分机制,用户甚至不需要主动关心这些;
最后再聊聊反向传播的工作原理,顾名思义它的数据量是从输出层到输入层逐层地进行计算梯度,并且利用这些梯度来进行更新网络参数以最小化损失函数,具体而言是这样的
- 首先我们需要进行前向传播,并且通过损失函数计算出误差(这个过程中每一层会记下自己的输入和输出)
- 从输出层开始往回逐层地进行如下行为,得到每一层的更新
- 计算自己的梯度:利用从后面传回来的“误差信号”(输出层则直接利用损失函数计算出的误差),结合自己这一层的输入,算出这一层权重 (
- 利用链式法则,将误差进一步上一层传递,传给上一层的误差=本层误差信号 × w(本层权重函数),直观理解就是告诉上一层:“因为我的权重 (w) 是这么大的,你传给我的任何一点偏差,都会被我放大 w 倍传给后面。所以,你要根据我的权重大小来调整你的输出。”
- 计算自己的梯度:利用从后面传回来的“误差信号”(输出层则直接利用损失函数计算出的误差),结合自己这一层的输入,算出这一层权重 (
- 参数更新:利用刚才算出的梯度,让权重朝着“误差减小”的方向优化,具体优化方式也有很多,最经典的涉及到一个学习率的问题,即每次更新的幅度多大~(读者可自行理解)
# 说回权重
综上来看,权重是一个非常重要的东西,模型参数越大,权重越多,模型的能力就越好但是也可能导致
- 训练速度太慢:权重越多要计算的东西就越多,计算量越大,那在恒定的计算强度下,就需要花更久的时间
- 模型放不下:咱们训练的时候要把权重都放进卡里才能利用GPU的计算能力对吧,那如果它的显存不够放不就完犊子了?当然也可以卸载到CPU甚至磁盘上,但是那都是后话了(当然还是极其不建议用磁盘的)
至此,我们回到了那俩核心问题上:训练太慢和模型放不下,下面让我们来讲讲这些并行方式如何解决这俩问题
# 一些概念
# 激活值
神经网络在前向传播时,每一层算出来并暂存的中间结果。训练时之所以要存它们,是因为反向传播要用这些中间结果来计算梯度,所以大部分前向传播的结果都会被存下来(或者开启recompute功能) 显存会受到模型参数量的影响,但是同时也收到seq_len和batch_size的影响;当bs过大时,无法通过tp并行来降低显存使用,只能通过cp和sp;
# DP数据并行
DP并行详解 (opens new window) 数据并行是指将相同的模型副本放在多个设备上,并将训练数据划分为不同的批次,每个设备处理一部分数据; 大概有这些要点
- 多个设备上存放相同的“模型结构”,即ATTN和FFN等的参数规模都是一样的,但是其权重可能不完全一样(每一轮结束后会进行通信然后同步参数)
- 实际中多用于单机多卡
- DDP:分布式单机多卡(现在最常用)
- 理解“把训练数据分为不同批次”:在训练配置中,我们会设置batch_size表示一个迭代中处理的样本总数,那么当使用dp的时候,实际上是把batch_size个样本分成了多个更小batch_size的样本,然后喂给多个设备;
# dp数据并行的通信
DP里最重要的通信就是AllReduce,这是一种集合通信 (opens new window),主要目的是将所有参与节点的数据聚合起来,并将聚合后的结果广播回所有的节点
具体allreduce的流程就不详细说了,重点说一下allreduce的通信量计算方式
# dp通信量计算
对于一个拥有
变量含义:
- FP32 (单精度):
- FP16 / BF16 (半精度):
- FP32 (单精度):
来解释一下为什么是这样计算的:
- 模型不会一次性把所有参数传递给邻居,而是将模型参数平均切分成 N 个小块。
- 假设我们有
个 , 模 型 参 数 被 切 分 为 个 小 块 , 记 为
- 初始状态:每个 GPU
拥 有 所 有 分 块 的 本 地 版 本 , 记 为 - 核心迭代流程:对于第
步 ( 从 到 - 发送动作:GPU
将 它 当 前 拥 有 的 第 号 分 块 发 送 给 它 的 下 游 邻 居 - 接收与累加:GPU
从 它 的 上 游 邻 居 那 里 接 收 到 一 个 分 块 ; 该 分 块 是 第 - 计算:GPU
- 发送动作:GPU
- 一共是
轮 , 因 此 每 卡 通 信 量 是
那么这样看,我们很容易想到DP解决的问题是模型训练的问题,同样的数据同样的模型,我多拿几个设备训练肯定是能获得近乎线性的效率提高的对吧,但是显存不够这事dp确实暂时一点没管,所以光用dp还是无法训练较大参数量的模型;
# Zero技术
可以先阅读(训练-并行技术)ZeRO系列 (opens new window)
zero是一个显存优化技术,其核心原理在于把模型的不同部分,划分到多个GPU上(减少冗余的存储),其技术实现可以分成三个阶段,每个阶段的显存占用逐渐减少,通信开销逐渐增大; 在详细讲解所有的zero阶段之前,我们需要再回顾一下,显存占用主要是哪几部分
- 参数,按照FP16的量化,那么就是2B大小
- 梯度,按照FP16的量化,那么就是2B大小
- 优化器(大头),会存储4B大小数据,加上一阶矩和二阶矩,一共4B*3=12B'
# 备注——通信量计算
下面把 ZeRO-1/2/3 在 一个 DP 组(大小
- 模型参数个数为
- 参数与梯度都是 FP16(每参数 2B),则
- 通信使用 ring 实现的经典代价(这是多数框架/库的近似上界):
- All-Reduce(AR)每卡通信量(发送+接收)约:
- Reduce-Scatter(RS)每卡通信量约:
- All-Gather(AG)每卡通信量约:
- All-Reduce(AR)每卡通信量(发送+接收)约:
其中
# Zero 1
只分片优化器状态:参数和梯度保持每张卡都有完整的一份,优化器状态分摊到N_d张卡上(dp的规模) 通信:类似传统的dp,只需要一次梯度all-reduce即可,主要是对梯度进行allreduce(梯度同步之后再本地更新参数,因此不需要参数同步) 显存下限依然受限于参数+梯度(4P)
通信量大小(假设模型大小为P个参数):
- allreduce:只需要梯度同步,|2P|=|G|
- 每卡通信量:
- 每卡通信量:
# Zero 2
分片优化器状态+梯度:只有参数保持每张卡都有一份,梯度和优化器状态均分摊到多卡 通信
- 反向传播结束时需要rs,从而每张卡得到分片梯度(在梯度分片的情况下,backward之后每张卡拿到本地完整梯度,全卡做reducescatter进行归约和切片,每张卡保留自己的那片)
- 如果仔细想的话,似乎还是会短暂的在每张卡上保留全量的梯度(例如在刚结束反向传播,还未开始rs之前),但是实际上会通过bucket来边反向边rs,rs之后立刻释放,从而不需要保留全量梯度
- 更新梯度后需要ag对所有卡的全量参数进行更新
下限依然受到参数大小的限制(2P)
每卡通信量:
代入
# Zero3
分片参数+梯度+优化器状态 通信
- 前向之前需要ag以得到该层的参数:每个rank把自己的那份发出去,同时接受别人的片,临时得到某一层的全量参数;然后进行前向计算,计算结束之后保留自己的分片
- 反向进行到第l层前需要拿到该层的权重(分片)和激活值(已有),因此进行
- ag获得该层的全量权重
- 计算梯度
- rs梯度,将梯度按照参数分片分发给对应的rank
- 几乎不需要DP通信,因为每个rank都有自己负责的参数,梯度(而不是全量的参数),因此只需要用自己的梯度更新自己的参数即可,在下一次进行前向/反向需要用到参数的时候再allgather一下
每卡通信量
代入
# TP张量并行
参考csdn文献 (opens new window) 张量并行是将模型中的张量进行拆分然后分配到不同的 GPU 上,每块 GPU 都可以得到所有层张量的部分参数(注意这里,这里是tp和pp的重要区别),这里相当于把模型横向切分,即每一层都切到一点;而不是把模型切成几层互相隔离的有序的(pp并行)
这是减少单个网络层的激活显存的唯一方法
# 1D张量并行
把同一层的参数矩阵分块进行相互独立的矩阵乘法计算,然后合并结果; 对一个单独的矩阵,我们可以很自然想到基于行和列进行拆分,称为行并行和列并行。
假设矩阵乘法是: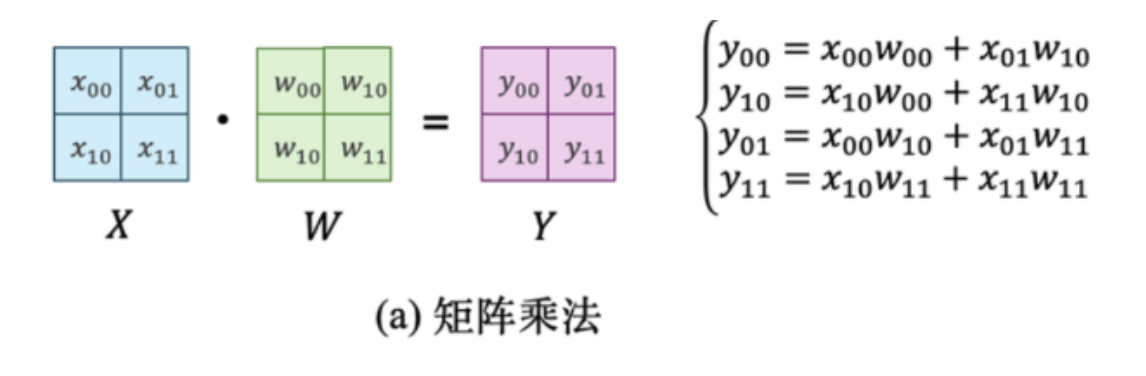
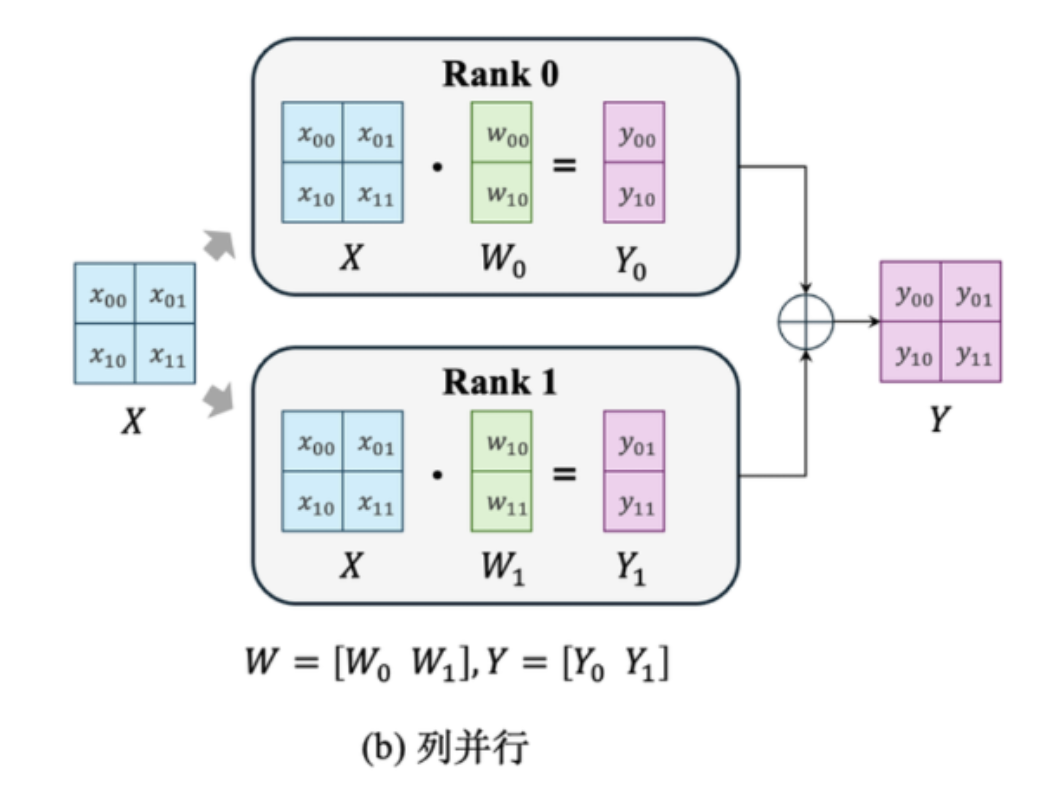
对于列并行,就是把W矩阵按照列分散到多个GPU上,最后再把结果聚合起来
同样的对于行并行,就是把W矩阵按照行分散到多个GPU上,最后再把结果聚合起来
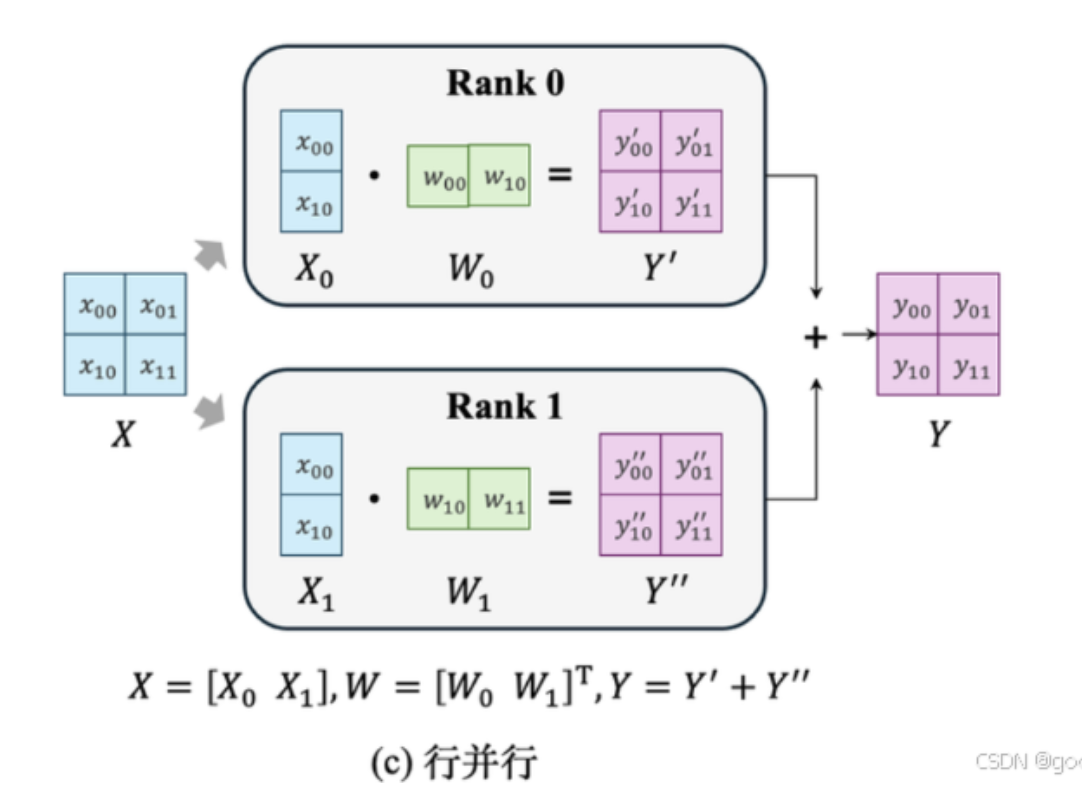
由于每一层对前一层的数据依赖,TP对设备间通信带宽要求较高,我们可以灵活使用行并行和列并行来减少前向计算中的allreduce; 观察到:行并行的输出形式恰好是列并行的输入形式,列并行的输出方式恰好是行并行的输入形式,因此不难想到,在前向计算中,这两种并行方式是交替使用的
- 例如,在一个包含两个线性层的FFN层中(nn.Linear和GELU),如果nn.Linear使用行并行进行划分,那么在经过GELU之前还需要进行一次allreduce,而如果一开始用列并行那么可以推迟到GELU之后;在FFN之后无论怎样都需要聚合结果;
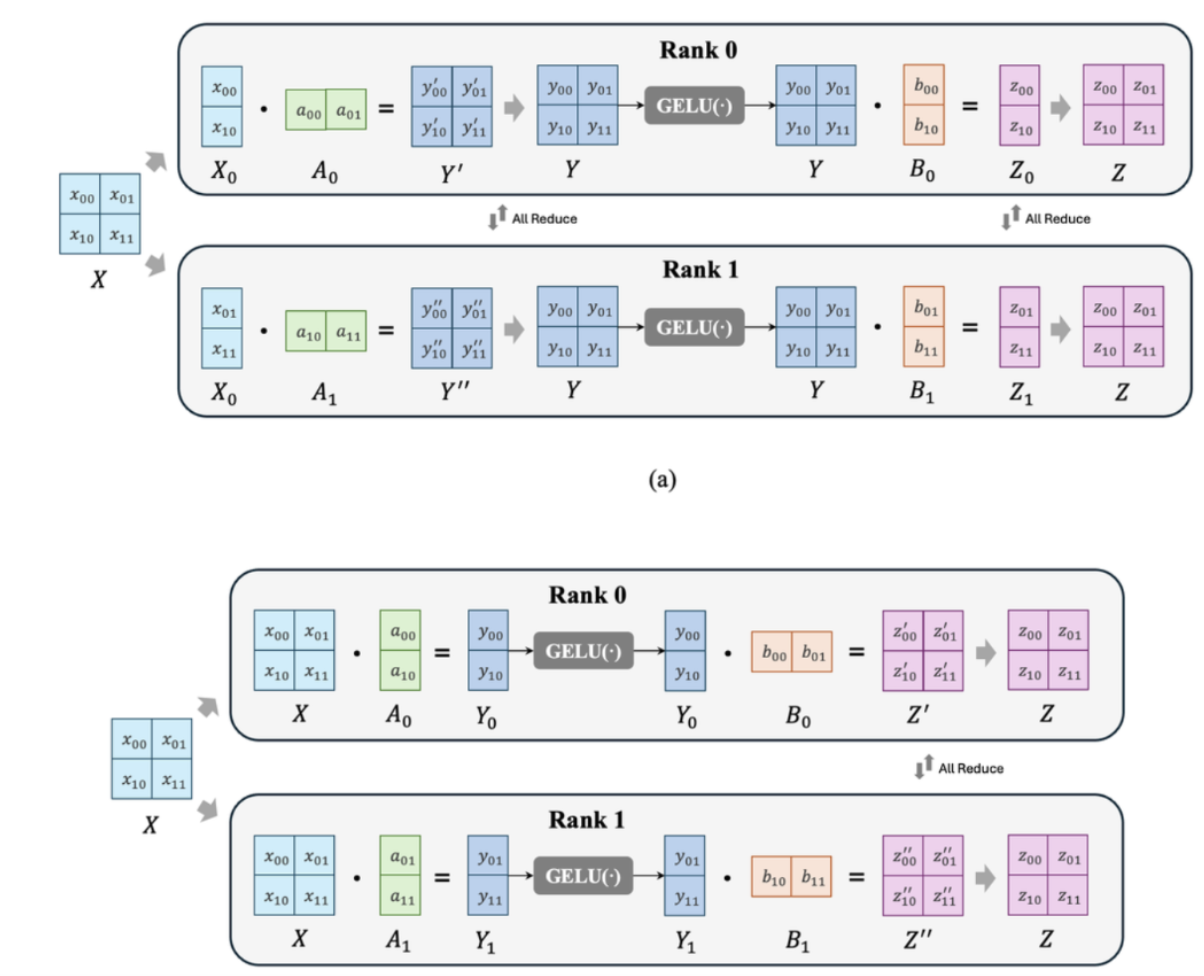
- 也比如注意力层MHA的并行方式,将qkv矩阵使用列并行分配到不同的gpu上,各自进行注意力计算后,得到表征 H0和H1,然后输入与线性层进行行并行运算,然后再将两个矩阵通过一次全收集操作相加,得到 MHA 层的输出
# 线性层通信量分析
线性层假设为
- 列并行
- 前向通信(典型):
- 反向通信(典型):为了算
- 前向通信(典型):
- 行并行
- 前向通信:
- 反向通信(典型):为了把
- 前向通信:
- 列+行并行
- 第一层列并行可不通信,第二层行并行必须通信:
- 第一层列并行可不通信,第二层行并行必须通信:
# Attention层通信量分析
Attention 里有三类大头:
- QKV 投影(线性层):通常按列并行切(输出维大)
- Attention 输出投影(线性层):通常按行并行切(接残差前要完整
- softmax / score 计算本身:若只做 TP(不做序列并行),多头分片后通常不需要跨卡通信;若引入序列并行/上下文并行会额外通信(这是另一条线)
因此注意力块里最常见、最稳定的一笔通信是:
综上,在只做 1D TP、且采用列+行配对的主流实现里,粗略可以把每个 block 的主要前向通信估成两次对
# 2D张量并行
1D张量并行中每个处理器仍需要存储整个中间计算图结果,这样往往占用过多显存结果; 2D 张量并行技术将输入数据、模型权重和层输出拆分成两个维度。与 1D 张量并行相比,它通常能做到更低的内存消耗(每张 GPU 只需要持有更小的分块)。
假设我们有 4 块 GPU,可以把一次矩阵乘法分块到每块 GPU 上执行。
将输入
- 在 Step 1 中进行
- 在 Step 2 中进行
将两步的计算结果相加,得到最终输出:
通信量分析暂不给出,欢迎读者自行计算
# PP流水线并行
流水线并行同样是拆分模型,但是和tp并行不一样的是,他是纵向拆分的,即将模型拆分成几个部分后,每个部分拥有完整的若干连续层(对比tp:每个部分拥有每个层的部分结构),这样就可以建立流水线了,当然这也导致了不同流水线之间需要进行通信;同时还可以利用流水线加快训练(减少空泡时间) 流水线并行目前流行的有三种Gpipe,1f1b,dualpipe(当然也有最朴素的流水线并行,我们成为Vpp)
首先提一些基本概念
- pp stage/rank,指的是将模型按照pp划分之后,按照前向传播经过的顺序依次经过的不同划分部分,比如pp=4的时候,就分了四个pp stage,那么当batch数据开始前向传播的时候,会依次经过pp stage1,pp stage2... (注意每个pp stage可能包含多个rank,因为可能在pp内部还有tp并行)
# 朴素流水线并行
最朴素的一种,只切分模型,不做其他任何优化,仅仅是节省了显存占用,但是引来了额外通信
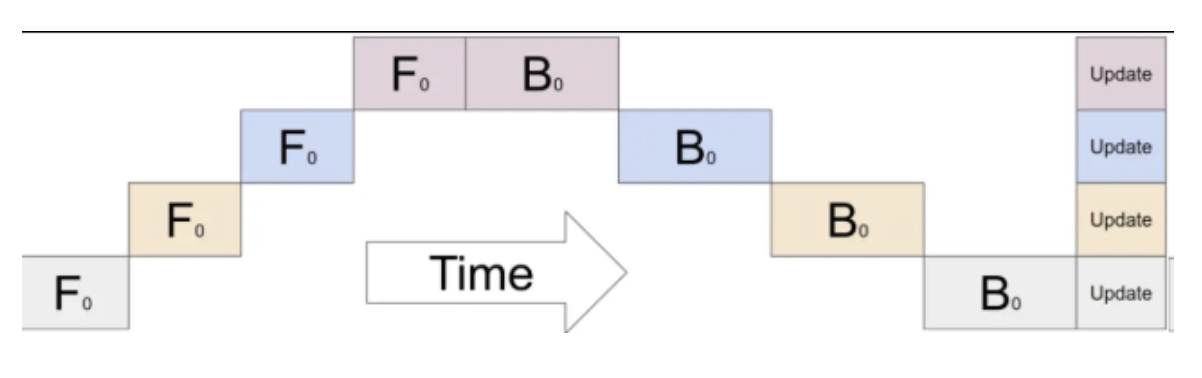 上图给出了pp=4的朴素流水线timeline,可以看到这里面存在很多空泡(即gpu在空转),这实际上极大浪费了计算资源
上图给出了pp=4的朴素流水线timeline,可以看到这里面存在很多空泡(即gpu在空转),这实际上极大浪费了计算资源
# 微批次流水线并行
微批次(MicroBatch)流水线并行与朴素流水线几乎相同,但它通过将传入的小批次(minibatch)分块为微批次(microbatch),并人为创建流水线来解决 GPU 空闲问题 其中Batch_size = Micro_batch_size * Micro_batch_num
# Gpipe
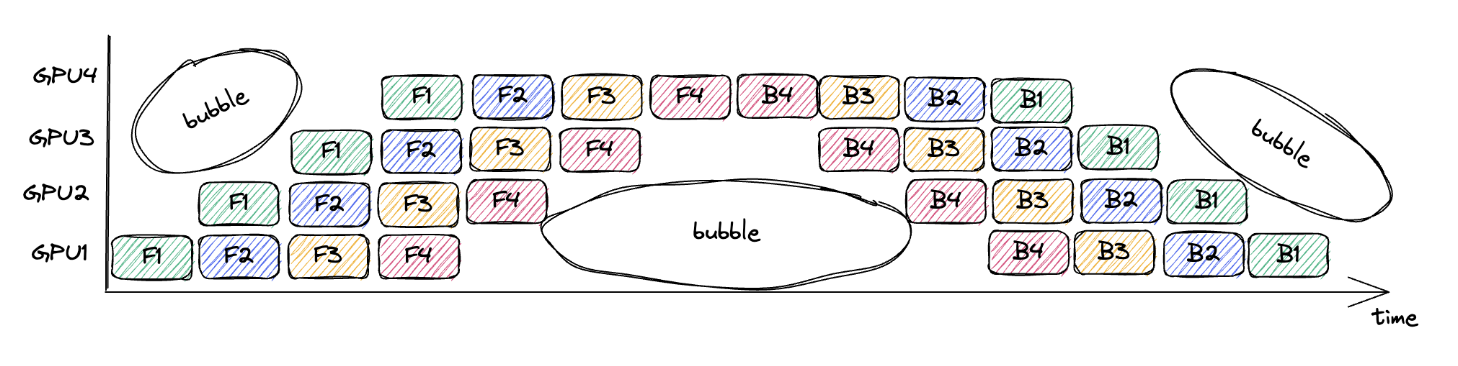 如上图,实际上是将本来的batch拆成了四个micro_batch,这样就可以利用多个microbatch的计算重叠来减少空泡时间;
假设pp并行深度为 n 和 microbatches 数量为 m
空泡时间比例:
如上图,实际上是将本来的batch拆成了四个micro_batch,这样就可以利用多个microbatch的计算重叠来减少空泡时间;
假设pp并行深度为 n 和 microbatches 数量为 m
空泡时间比例:
显存利用:增加批量大小会线性增加缓存激活的内存需求,我们可以通过 重计算-recompute来降低显存需求;具体来说,我们不会缓存计算梯度所需的所有激活,而是在反向传递过程中动态重新计算激活,这降低了内存需求但增加了计算成本
- 若无重计算,那么缓存激活为
- 若有重计算,则只缓存层边界上的输入(即缓存从前一个 GPU 发送给我们的张量,或者说上一个GPU最后的计算结果),缓存占用为
# PipeDream
之前的朴素pp和Gpipe都是F-then-B的模式,即一定是先做完全部的Forward然后再做Backward,该模式由于缓存了多个 micro-batch 的中间变量和梯度,显存的实际利用率并不高;
于是我们引入了一种新的模式1F1B:一种前向计算和反向计算交叉进行的方式,最基本的就是Pipedream
在 1F1B 模式下(这里重点讨论的是非交错1f1b),前向计算和反向计算交叉进行,可以及时释放不必要的中间变量
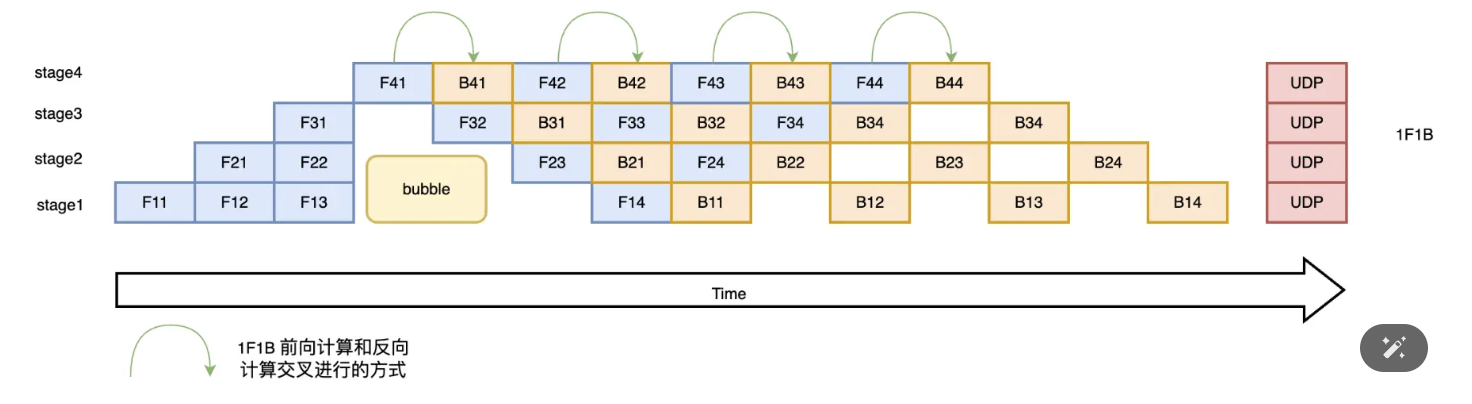 如图所示:以 stage4 的 F42(stage4 的第 2 个 micro-batch 的前向计算)为例,F42 在计算前,F41 的反向 B41(stage4 的第 1 个 micro-batch 的反向计算)已经计算结束,即可释放 F41 的中间变量,从而 F42 可以复用 F41 中间变量的显存;
如图所示:以 stage4 的 F42(stage4 的第 2 个 micro-batch 的前向计算)为例,F42 在计算前,F41 的反向 B41(stage4 的第 1 个 micro-batch 的反向计算)已经计算结束,即可释放 F41 的中间变量,从而 F42 可以复用 F41 中间变量的显存;
更严谨地说:一个阶段(stage)在做完一次 micro-batch 的前向传播之后,就立即进行 micro-batch 的后向传播(如果可以的话),然后释放资源,那么就可以让其他 stage 尽可能早的开始计算;
空泡时间比例:
流水线具有异步性,面对流水线带来的异步性,1F1B 使用不同版本的权重来确保训练的有效性。即保存每个microbatch对应的权重版本来确保训练的有效性,反向处理同一个 micro-batch 时,强制使用它前向对应的那一版权重
那么其实还有交错的1F1B,采用虚拟流水线(virtual pipeline),在设备数量不变的情况下,分出更多的流水线阶段(pipeline stage),以更多的通信量,换取流水线Bubble比率降低;如下图所示对比
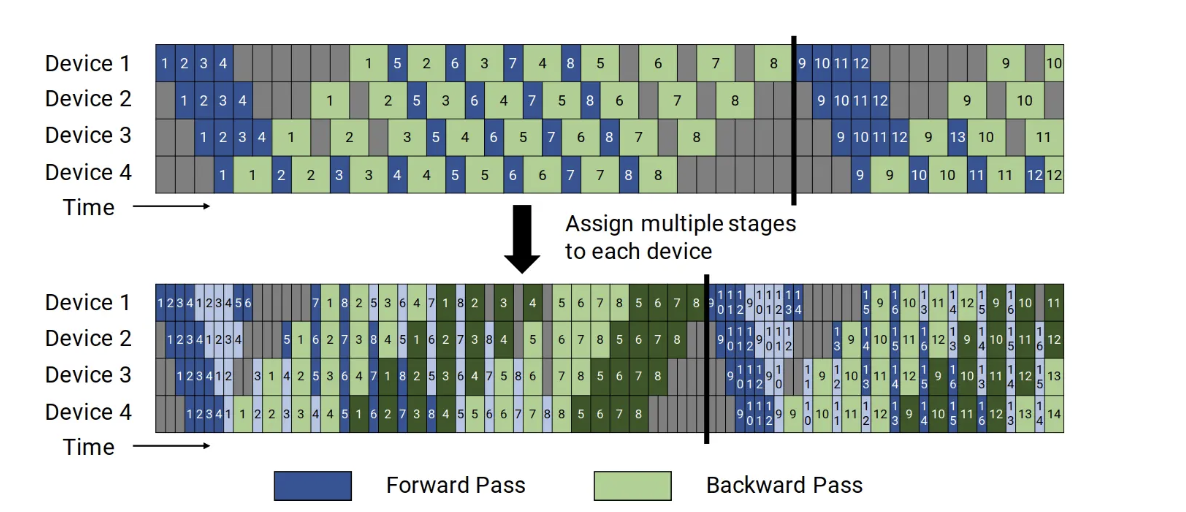
具体来看,在之前非交错式调度中,设备1拥有层1-4,设备2拥有层5-8,以此类推;但在交错式调度中,设备1有层1,2,9,10,设备2有层3,4,11,12,以此类推。在交错式调度模式下,流水线上的每个设备都被分配到多个流水线阶段(虚拟阶段,virtual stages),每个流水线阶段的计算量较少。
这种模式既节省内存又节省时间。但这个调度模式要求 micro-batch 的数量是流水线阶段(Stage)的整数倍。
# DualPipe
详细可见知乎,这里不做详细说明 (opens new window)
# PP通信量分析
PP(流水线并行)的跨卡通信主要发生在相邻 stage 的边界:前向传一次激活,反向再传一次激活梯度。因此通信量的计算抓住两点:边界张量大小 × 传输次数。
# 1)边界张量大小(Bytes)
若切分点在 Transformer block 边界,通常传的是 hidden states,形状约为
设通信 dtype 字节数为
# 2)单次训练 step 的总通信量(Bytes)
设 PP 深度为
前向通信量:
反向通信量:
合计:
展开得:
# 3)常用口径:固定 global batch
若一个 step 的 global batch 为
# EP专家并行
在看ep专家并行之前,可以看一下moe模型浅谈
# MOE在DP时的问题
首先我们会发现一个问题,如果你只用普通的数据并行(DP)去训练 MoE,随着专家数
这里给出一个case,基本参数为
- 有
- 每张设备的 micro-batch size 是
所以全局 mini-batch size 是 - 模型有
- 每个样本(或 token)路由到
普通 DP 的问题:在每个 DP worker 内部,它只看到自己那份
- 每个 worker 上,每个专家分到的样本数大约是
由于实际里
- 也就是每个专家每次只处理很少 token → GEMM 很小很碎 → GPU 利用率差 → 难扩展(专家越多越糟)。
于是这个时候提出了EP并行——Expert Parallelism
# EP并行如何作用在DP内
让专家参数跨 DP worker 共享(专家分片放到各卡上),而非专家部分仍按 DP 复制;然后把不同 DP worker 产生的 token 经过 Gate 后做 All-to-All 重分发,按 expert id 聚合到拥有该专家参数的设备上计算。 说直白点,就是本来不同DP组之间互不联系,每个DP组有自己的tokens,组内的专家也只从本DP组内取路由的tokens ==> 现在将专家分散到不同DP组内,然后每个专家就从所有的DP组内取路由的tokens了
依然刚刚的配置
- 总共有 256 个 expert
- 有 32 个 DP worker
- 那么每个 worker 上放 8 个 expert(256/32=8)
- 所有 worker 的样本经过 gate 后,被重新分发到对应 expert 所在的 worker
这样一来,对于“某一个 expert”来说,它不再只吃到“某一张卡上的那点 token”,而是能从整个 EP 组/全部 DP worker 聚合 token。于是平均每个专家每 step 得到的样本数变为:
对比普通 DP(每卡本地)下的
当然,我们也可以很容易想到,把专家分布在多个GPU上之后,显存占用就降低了;
# EP的通信
EP(Expert Parallelism)里最“硬核”的部分就是 token 为了去到它被分配的 expert 所在 GPU,需要跨设备搬运。因此通信主要发生在 每个 MoE 层的前向与反向,并且通常以 All-to-All(或等价的 AlltoAllv) 形式出现:一次把 token 发出去(dispatch),一次把专家输出收回来(combine)
通信发生在什么时候:
- 前向(Forward)
- Router 在本地算完 Top-k 之后:每个 token 已经知道要去哪些 expert(以及对应 gate 权重)。
- Dispatch(All-to-All):把属于远端 expert 的 token hidden states 打包发到拥有该 expert 的 GPU(同卡的不用过网)。
- 远端 GPU 本地执行专家 FFN(grouped GEMM / fused MoE)。
- Combine(All-to-All):把专家输出再发回 token 的“来源 GPU”(或需要它的 GPU),并按 gate 做加权合并、还原原始顺序。
- 反向(Backward)
- 梯度路径基本镜像前向:
- 从 MoE 输出梯度出发,先按 combine 规则拆分到各 expert 输出位置;
- 把属于各 expert 的梯度通过 All-to-All 发回 expert 所在 GPU(对应 forward 的 dispatch 方向);
- 在 expert 上做 FFN backward 得到对输入 token 的梯度;
- 再通过 All-to-All 把 token 输入梯度送回原 GPU(对应 forward 的 combine 方向)。
- 所以多数实现里,一个 MoE 层通常表现为:前向 2 次 All-to-All + 反向 2 次 All-to-All(实现细节可能融合/重排,但量级接近)。
- 梯度路径基本镜像前向:
设:
- EP 组大小为
- 每张卡本地 token 数为
- hidden size 为
- Top-k 为
- 激活精度每个元素字节数为
那么每张卡在 dispatch 需要“发送”的激活元素数,近似是
前向 dispatch(每张卡跨卡通信字节数,近似)
前向 combine(量级与 dispatch 同阶)
所以单个 MoE 层 前向总跨卡通信 近似:
反向通常也有两次类似 All-to-All(把梯度送到 expert、再把输入梯度送回 token 所在卡),因此单层 反向总跨卡通信 近似:
合起来得到单层 MoE 的 前后向总跨卡通信 粗估:
# SP序列并行
csdn的参考文献 (opens new window) 在 Transformer 模型中,self-attention 模块的显存占用是与输入序列长度(sequence length)的 2 次方成正比,导致序列太长时可能导致一张 GPU 显存放不下的瓶颈,这给超长序列训练带来极大的挑战; 因此为了节约显存,我们引入了SP并行
SP并行是指把“序列长度维度”切开,让多张 GPU 各自处理一段 token,从而把一些原本需要“每张卡都存一整条序列的激活”的地方摊薄,尤其在大 batch/长上下文时能明显省显存;同时它常和 TP配套,用来减少 TP 下某些算子的激活冗余;
SP 特别适合的场景是:很多操作本质上是“对每个 token 独立地做同样的事情”(LayerNorm、Dropout、MLP 等),把 token 分到不同卡上做,计算逻辑完全一致,峰值显存按 1/G 缩小,对于张量维度 [sequence_length, batch_size, hidden_size] 来说,是在 sequence_length维度做功因此SP只作用于LayerNorm和Dropout这两层,完全不处理其他层,根本原因是:这两层不需要跨序列交互;
大致流程
- 按序列切分输入:
- 大多数逐 token 层本地执行(norm、MLP 中间激活等)
- 在少数边界做通信以匹配算子/并行所需布局:
- 常见是 all-gather(临时拼序列)与 reduce-scatter(算完再切回去)
- 主要是FFN/MLP的输出层
- 输出仍保持序列分片,进入下一层重复
| 显存组成部分 | 性质 | 相对占比(估算) | 对应的“削峰”技术 |
|---|---|---|---|
| 优化器状态 | 静态 | 极高(约占模型本身的 3-4 倍) | ZeRO-1 / ZeRO-2 (将状态切分到多卡) |
| 激活值 | 动态 | 极高(随 Batch/Seq 暴增) | Activation Checkpointing (重计算)、Sequence Parallelism (SP) |
| 模型权重 | 静态 | 中等 | ZeRO-3 / Tensor Parallelism (TP) |
| 临时算子 Buffer | 瞬时 | 较低 | 算子融合(FlashAttention)、优化通信 Buffer |