 Transformer结构初窥
Transformer结构初窥
这里暂时放一下之前学习Transformer架构的笔记,个人认为掌握这些之后就暂时足够了,当然后续还会继续整理其他结构~
# 学习路径概览
- Transformer 核心结构:理解模型的前向传播逻辑。
- KV-cache 机制:理解生成式模型如何通过缓存换取速度。
- PD 分离架构:理解推理系统中“预填充”与“解码”的资源矛盾。
- AE 分离与 Prefetch:针对长文本和多轮对话的极致优化。
# Transformer
在写本篇blog时参考了以下博客:
深度学习|基础算法】快速入门Transformer教程(小白友好向) (opens new window)
# 1. 基本结构
Transformer 由 Encoder(编码器,用来“读懂/编码”输入序列) 堆叠与 Decoder(解码器,用来“生成/解码”输出序列) 堆叠组成,通常包含相同的层数。输入输出都是 token(词元,分词后的最小单位,可以是一个词、一个字或一个子词) 的序列(sequence,一串按顺序排列的 token)。
- 最开始有一个词嵌入层(Embedding,把离散的 token ID 变成连续向量表示),仅发生在最底层的encoder(最靠近输入的一层,下图中最下面的Encoder那里)
- Decoder 的最底层同样会对输入 token 做词嵌入;嵌入也同样只在底层发生一次,上层处理的是隐藏表示(hidden states,中间层产生的向量特征,是从sequence经过一系列Encoder输出的中间结果)
- Transformer 不包含循环结构(RNN 式的逐步递归,RNN的可参考图示 (opens new window)),顺序信息由位置编码(positional encoding/embedding,把“第几个位置”编码成向量信息)提供。位置编码可以是固定的形式(sin/cos,按公式生成的固定向量),也可以是可学习的位置向量(learnable,训练中自动更新的参数),通常与 token embedding(词嵌入向量)相加后送入网络
参考图示:![]()
# 2. Encoder
# 2.1 Encoder 的层结构
- 一个Transformer一般有n个encoder,每个encoder包括一个 self-attention(自注意力,让序列中每个位置根据相关性“关注”其他位置) 和一个FFN(Feed-Forward Network,前馈全连接网络,对每个位置做非线性变换)
- FFN 形式为:
其 中 为 权 重 矩 阵 ( 可 学 习 参 数 ) , - FFN 对序列中每个位置独立应用同一组参数(position-wise,逐位置共享参数地计算),即每个token都进行相同的计算过程
# 2.2 Encoder 输出的用途
Encoder 最终输出序列表示 Z(编码后的整段序列向量表示)
在 Decoder 的 encoder-decoder attention(交叉注意力,decoder 用来读取 encoder 输出信息的注意力层;也称 cross-attention)中,Z 会通过线性变换(linear projection,用矩阵乘法把向量映射到新空间,本质也就是一系列矩阵乘法)得到 K/V(Key/Value,注意力机制里用于“匹配”和“取信息”的向量);Decoder 当前状态产生 Q(Query,用来发出“我要找什么信息”的向量),从而让 Decoder 在生成时读取源序列信息。
# 3. Decoder
# 3.1 Decoder 的层结构
- n个decoder,每个decoder包括一个 masked-self-attention(带遮挡的自注意力,禁止看到不该看到的位置,比如说我给一句话然后给出前四个字然后预测其中第五个字的时候,理论上不应该让机器“看到”后面的字是什么),一个 encoder-decoder attention(交叉注意力,读取 encoder 输出),一个FFN(前馈网络)
- encoder的输出Z,会经过变换得到K/V矩阵(把 encoder 输出映射成注意力使用的 Key/Value),作为输入传入给每个decoder的encoder-decoder attention层,作为他们的K/V矩阵
- decoder拿到encoder生成的K/V矩阵后,开始逐个生成tokens(自回归生成,一次生成一个 token),并且之前生成过的tokens也会作为输入下一个时间步(time step,生成过程中的第几步)中被馈送到底部的解码器,同样会经历词嵌入(Embedding,把 token 变成向量)(开头有一个特殊token:SOS,Start Of Sequence,序列开始标记)
- 经过了所有的decoder之后,最后会输出一个浮点数向量(hidden vector,表示当前位置的特征),因此再用一个线性层(MLP,多层感知机;可以理解为依然是一系列线性变换,这里线性层的目的是输出一个维度是“词表”大小的向量,相当于得到了每个词在当前位置出现的概率)+一个softmax层(把一组数变成概率分布的函数)来处理,选择概率最高的单元格(即选择概率最大的词表项作为输出 token);
# 3.2 Mask 的类型与作用
- Padding mask(填充遮罩,屏蔽 padding token 的影响):忽略 padding token(padding,为了对齐长度而补的占位符),避免注意力分配到填充位置
- Causal mask(因果遮罩,也叫 look-ahead mask,前瞻遮罩):用于 masked-self-attention,生成第 t 个 token 时只能看见位置不超过 t 的 token,不能看未来 token(保证生成是“从左到右”的)
下面把你这一段的 Self-Attention 讲得更细一些,重点补全三件事:张量形状、逐步计算流程、以及为什么要缩放与 softmax。
# 4. Self-Attention
# 4.1 Q/K/V 的构造
对每个 token,先有它的输入向量表示
- self-attention,对于每个单词我们会用它(已经通过词嵌入转化为词嵌入向量)去分别乘以Q、K、V矩阵(可学习的投影矩阵,把输入向量变成 Query/Key/Value),得到三个向量(通常维度小于词嵌入向量,这是为了让多头注意力的计算更加流畅);
把单个位置写成公式,就是三次线性变换:
把整段序列堆叠成矩阵更直观。设序列长度为
- 输入矩阵:
后 者 的 意 思 是 维 度 是 的 所 有 矩 阵 形 成 的 集 合 - 三个投影矩阵(单头情形):
- 则
通常设模型维度为
# 4.2 深入理解(按第 i 个 token举例)
Self-attention 对第
- 在计算第i个token的时候,用qi(第 i 个位置的 Query 向量)去与k1、k2...(各位置的 Key 向量)分别做乘法(dot product,相似度计算,本质上也是矩阵乘法,只是有一个维度变成1了),得到每个token对应的k,v向量(与该位置相关的 Key/Value,v向量是每个token固定的属性,可以类比value和key向量为商品i本身具有的价值和商品i对当前token的市场价值)
点积得分(未缩放)为:
把对所有
- 然后对所有的score(注意力分数,相似度结果)除以
缩放后:
Q:为什么要除以
- 将每个位置的v向量(Value,携带实际内容信息的向量),乘以该位置上的softmax分数(归一化后的注意力权重),然后相加等到每个token在self-attention层最后的输出(加权求和后的新表示)
# 计算步骤
先对
再加权求和得到输出:
这里的含义是:第
# 5. 多头注意力(关注不同的特征,然后拼接到一起,用多个小头代替大头x)
- 多组Q,K,V矩阵,随机初始化(初始化参数的起始值);每个Q/K/V的集合用于将输入编码投影到不同的表示子空间(representation subspace,不同的特征空间,让不同头学不同关系)中
- 最后把多个注意力的输出在列方向上拼接(concat,按特征维度把向量接起来)后,还需要乘以一个专门的权重矩阵(输出投影矩阵,把拼接结果映射回模型维度)
- 将多个头的信息进行二次加工和深度融合(融合不同头学到的关系)
- 保持维度一致性(多头注意力每个输出的为原始维度/head_num,即每头维度为
# 6. 残差连接与归一化
- 残差网络(residual connection,把输入直接加到子层输出上,缓解梯度消失并稳定训练)存在于Transformer之中
- encoder中,每个ffn和self-attention都有残差网络,并且伴随着Normalize(归一化,通常指 LayerNorm,把特征按维度标准化以稳定训练)
- decoder中,每个ffn和self-attention还有 encoder-decoder attention 都有残差,并且伴随着Normalize(LayerNorm)
常见实现分为两类:
- Post-LN(后归一化):子层输出与残差相加后再做 LayerNorm (归一化 (opens new window),即按照数值进行缩放,使得其稳定在可控数值范围内)
- Pre-LN(前归一化):先做 LayerNorm 再进入子层,子层输出与残差相加
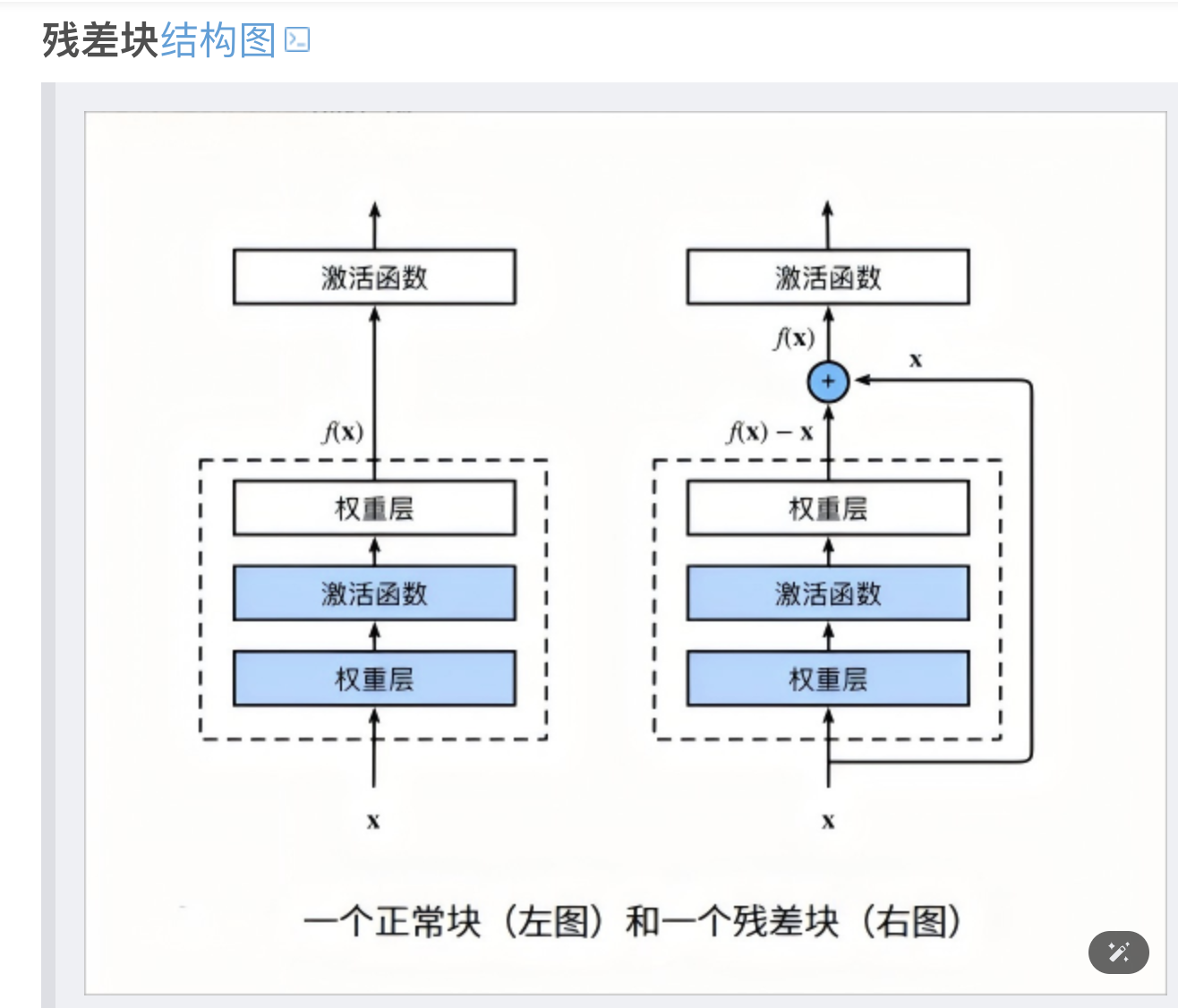 看图应该就很容易知道残差网络在干什么了,其实就是在数据进入某一层之后,把输入与该层的输出相加一遍
看图应该就很容易知道残差网络在干什么了,其实就是在数据进入某一层之后,把输入与该层的输出相加一遍
# 7. 形状与复杂度
设序列长度为
# 8. 常见三种 Transformer 形态
| 结构 | 注意力特征 | 典型任务 | 代表模型 |
|---|---|---|---|
| Encoder-only(仅编码器) | 双向 self-attention(可同时利用左右上下文) | 表征(representation learning,学习文本特征)、分类、检索 | BERT |
| Encoder-Decoder(编码器-解码器) | 编码 + cross-attention + 自回归解码 | 翻译、摘要 | T5、BART |
| Decoder-only(仅解码器) | causal self-attention(只看历史,不能看未来) | 生成式建模(language modeling,生成文本) | GPT |
# 总结一哈
总结一下,流程大概就是:
- 输入 token 经过 embedding(词嵌入)并加入位置编码后进入 Encoder;Encoder 用 self-attention(自注意力)聚合上下文信息,再用 FFN(前馈网络)做非线性变换,得到输出表示 Z
- Decoder 先用 masked-self-attention(带因果遮罩的自注意力)屏蔽掉不该看的数据,再用 encoder-decoder attention(交叉注意力)读取 Encoder 输出(作为 K/V),逐步生成 token
- 最后通过线性层与 softmax 得到词表概率分布,训练用交叉熵,推理按自回归方式生成。
# KV-cache:推理速度的基石
KV-cache 深度解析 (opens new window)
模型逐个生成 Token 时,需要用到之前所有词的
- 核心作用:省略了对历史 Tokens 的
- 适用场景:仅在 Decoder 端的生成步骤中发生(如 GPT 系列或 T5 的解码部分)。
- 注意:像 BERT 这种 Encoder-only 模型不涉及生成,因此不使用 KV-cache。
# PD 分离:推理系统的架构优化
# 1.性能衡量指标
- TTFT:首 Token 时延。
- TPOT:平均输出词元时间(D 阶段总时间 / 输出 Token 数)。
- Throughput/Goodput:吞吐量(TPS 或 RPS)。
- MFU:模型算力利用率。
- SLOs:服务级别目标(时延、可用性、错误率的量化阈值)。
# 2.P(prefill) 与 D(decode) 的矛盾
- P (Prefill):读入用户 Prompt,一次性计算 KV-cache。计算密集型,追求高吞吐。
- D (Decode):基于缓存逐个蹦词。内存带宽密集型,追求低延迟。
- 为什么要分离? 资源抢占会导致 Prefill 阻塞 Decoding,造成明显的卡顿。
# 3.工作流程
- P-Node (Prefill 节点):快速扫一遍输入,算出初始 KV-cache。
- Transfer (传输):通过高速网络(如 RDMA)将 KV-cache 传给 D 节点。
- D-Node (Decoding 节点):拿着接力棒,一个字一个字往外吐词。
# AE 分离:针对多轮对话的精细化
Prefill 阶段可以进一步细分为两种形态:
- E (Extend):全量预填充。处理新文档或新对话,计算密集型(算力瓶颈)。
- A (Append):增量预填充。处理多轮对话,访存密集型(带宽瓶颈)。
# AE 特性对比
| 特性 | Extend (E) | Append (A) |
|---|---|---|
| 计算量 | 极高 | 较低 |
| 瓶颈 | 算力 (TFLOPS) | 内存带宽 |
| 缓存状态 | 冷启动 (Miss) | 缓存重用 (Hit) |
# 核心技术:Prefix Caching (前缀缓存)
系统将对话历史的 KV-cache 像“积木”一样存在全局存储层。当新对话发起时,通过 Hash 匹配历史记录,直接“挂载”旧缓存,仅计算新增的少量 Token。
# Prefetch Critical KV:长文本传输优化
在 PD 分离架构中,长文本的 KV-cache 体积巨大(可达 GB 级),传输延迟会造成推理停顿。
关键动作:
- 层级流式传输 (Layer-wise Streaming):计算完一层传一层,实现计算与通信的 Overlap。
- 优先级调度 (Priority Transfer):优先传输启动推理循环所必需的 KV 块。
- 预分配与预加载:调度器提前通知 D 节点准备显存,并将公共前缀从内存提前加载至显存。